 Keep It Simple Veille et digital, avec une dose de stratégie
Keep It Simple Veille et digital, avec une dose de stratégie
Il existe plusieurs outils gratuits pour exporter des résultats d’une recherche Twitter dans un tableur. Mais ces outils sont limités par l’API du réseau social : vous ne pourrez donc pas enregistrer les tweets ayant été publiés 7 jours avant votre requête. Pour contourner ce problème, je vous propose de découvrir ma méthode préférée : le scraping de la page de résultats.

Cette méthode est similaire à celle que je vous proposais pour exporter les membres d’une liste Twitter dans un tableur (lire ici). Nous allons également utiliser Scrape Similar. Cette extension est plus que précieuse pour tout professionnel du web, puisqu’elle vous permet d’extraire (« scraper » dans le jargon technique), très facilement le contenu structuré d’un site.
Une fois l’extension installée, nous allons procéder à notre recherche sur Twitter. Prenons un exemple d’actualité : l’analyse des tweets à propos du chômage des deux candidats finalistes de la primaire de la gauche, depuis leur inscription sur Twitter.
Construisez votre requête grâce aux opérateurs de recherche Twitter, puis sur la page de résultats, sélectionnez « récemment » pour obtenir l’ensemble des tweets qui répondent à votre requête :
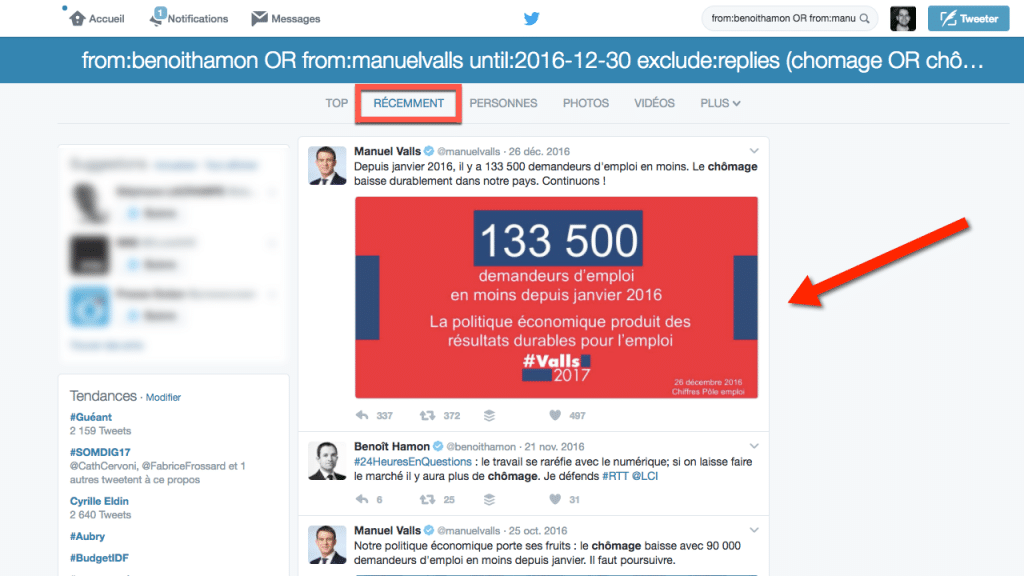
cliquez ici pour accéder à cette page de résultats
Une fois sur votre page, scrollez tout en bas de la page de résultats pour faire apparaitre l’ensemble des messages, jusqu’à faire apparaitre le logo de Twitter et le texte « Retour en Haut ». Si vous avez un grand nombre de tweets, je vous suggère d’utiliser l’extension pour Chrome « Simple Autoscroll » qui fera le travail à votre place.
Sélectionnez ensuite un tweet en mettez en surbrillance le nom complet de l’émetteur, son nom d’utilisateur et le texte du tweet, puis effectuez un clic droit. Dans la fenêtre qui s’ouvre, cliquez sur « Scrape Similar » :
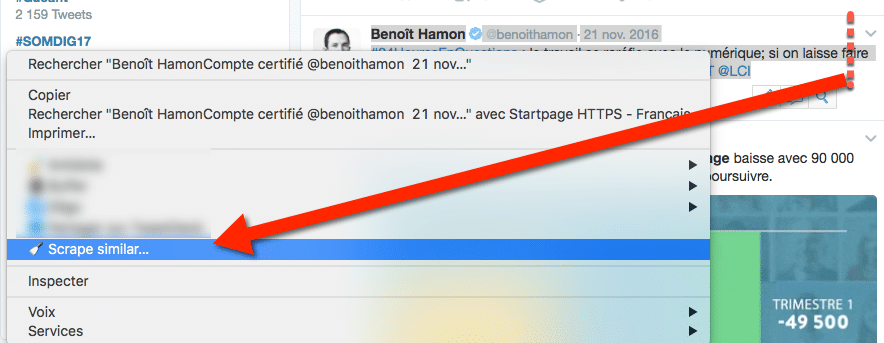
Une pop-up devrait s’ouvrir sur votre ordinateur et afficher des informations structurées de la façon suivante :

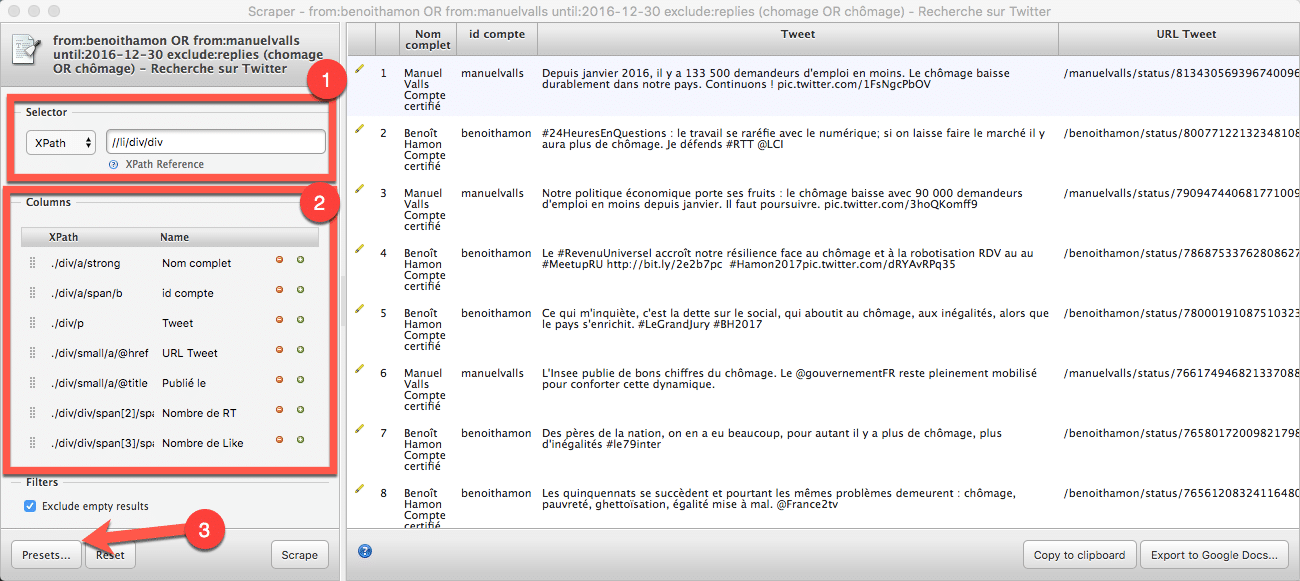
Avant de poursuivre, assurez-vous que dans Selector > Xpath (en haut à gauche), le chemin soit le suivant : //li/div/div
A ce stade, l’ensemble des données sont bien reconnues, mais il reste à créer les colonnes de votre futur fichier. Pour cela, dans Columns, entrez les informations suivantes :
- Xpath : ./div/a/strong (Nom complet)
- Xpath : ./div/a/span/b (id compte)
- Xpath : ./div/p (Tweet)
- Xpath : ./div/small/a/@href (URL Tweet)
- Xpath : ./div/small/a/@title (Publié le)
- Xpath : ./div/div/span[2]/span/span (Nombre de RT)
- Xpath : ./div/div/span[3]/span/span (Nombre de Like)
A la fin de ces réglages, cliquez sur « Presets » pour enregistrer ces paramètres. Cela vous évitera de refaire cette manipulation lors de prochains exports Excel.
Notez que « Name » équivaut à l’étiquette de votre champ. Vous êtes libres de les nommer comme bon vous semble et d’ajouter ceux dont vous avez besoin. Par ailleurs, pour ajouter une colonne, cliquez sur le petit (très petit même) icône + après le champ « Name ». De la même façon s’il y a un champ dont vous ne souhaitez pas, vous pouvez le supprimer avec l’icône -.
A la fin de votre manipulation, vous devriez ainsi avoir quelque chose qui ressemble à cela :
Ensuite, il ne vous reste plus qu’à exporter vos données dans votre tableur préféré :
- en ligne dans Google Documents : « Export To Google Docs »
- en local sur Excel ou Open Office : « Copy To Clipboard », puis en collant vos données
Dès que vos tweets sont importés dans votre tableur, effectuez quelques retouches pour nettoyer votre fichier avant d’effectuer vos analyses (statistiques descriptives, analyse sémantique, etc.).
Retouche 1 : supprimez les lignes vides, qui correspondent aux likes de vos abonnements sur les tweets de votre page de résultats (ce que Twitter appelle les « social proofs », son système de recommandation sociale). Pour cela, filtrez les lignes où la colonne A (Nom Complet) est « vide » puis supprimez les.
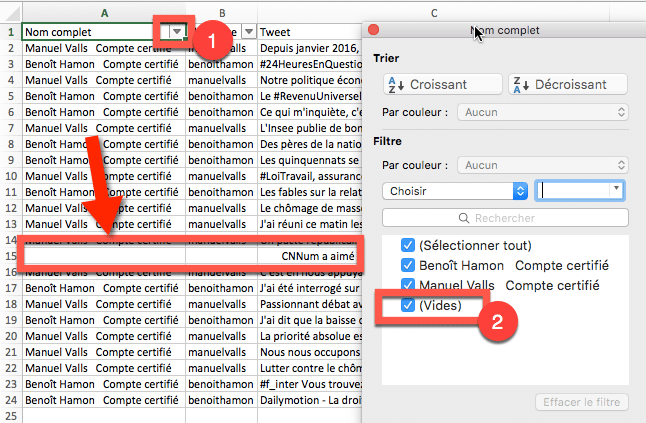
Retouche 2 : Transformer la colonne D du lien URL du Tweet en lien hypertexte cliquable pour y accéder directement en ligne.
Pour cela, insérez une colonne en E, puis combinez deux formules : CONCATENER pour créer le lien URL sous la forme http://twitter.com, puis LIEN_HYPERTEXTE pour rendre le lien actif. Dans notre exemple, cela donne la formule : =LIEN_HYPERTEXTE(CONCATENER(« https://twitter.com »;D2)). Une fois les liens hypertextes créés, masquez la colonne D pour ne pas perdre le lecteur :
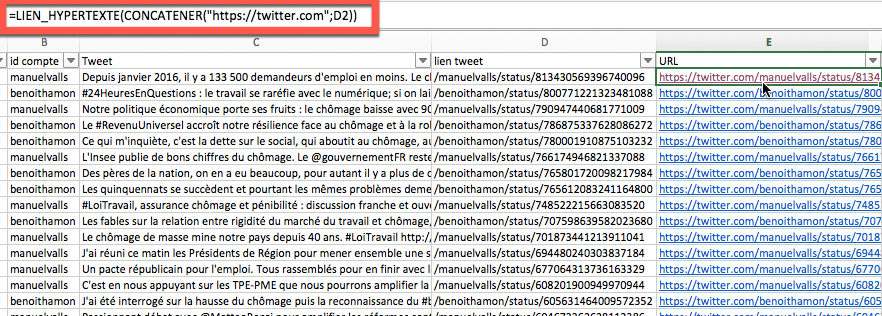
Vous pouvez également retoucher les autres colonnes en fonction de l’utilisation que vous souhaitez réaliser de ces tweets par supprimer les termes « Retweets » ou « J’aime » via la fonction rechercher/remplacer. A la suite de quoi vos analyses sont simples à réaliser grâce aux tableaux croisés dynamiques.





Bonjour Brian,
Merci pour ce blog dont les ressources sont si utiles pour les veilleurs !
A propos de cette SUPER technique de scraping, je viens de constater qu’elle ne fonctionne plus depuis le changement de l’interface Twitter en juillet. Le X-Path ne matche plus…
Vous êtes-vous déjà penché sur le sujet ? Auriez-vous pu revoir le chemin permettant à nouveau de récupérer les résultats d’une recherche Twitter ?
Un grand merci par avance !
Bonsoir,
J’ai installé l’extension Scrapper afin de pouvoir extraire des tweets pour mon mémoire de fin d’études. Cependant, de mon côté, ça marche sur google mais une fois sur les résultats de recherche twitter lorsque je mets en surbrillance un tweet et que je clique sur « Scrape Similar » la console s’ouvre mais aucun texte ne s’affiche. Est-ce normal ?
Excellente soirée à vous,
Clémentine
Bonjour,
J’ai le même problème. Impossible de sauvegarder les tweets.
Bonjour, et premièrement merci beaucoup pour cette astuce.
Est il possible via scrape similar de recueillir si oui ou non une photo a été partagée?
Cordialement